DocFetcher
DocFetcher ist eine Open-Source-Desktop-Suche für Dateien, entwickelt von Tran Nam Quang, und erstmals um 2006/2007 erschienen. Das Programm durchsucht unter anderem Microsoft-Office-Dokumente, OpenDocument-Formate, PDFs, HTML-Dateien sowie einfache Textdateien und unterstützt Unicode sowie verschachtelte Archivformate wie ZIP, 7z, RAR oder TAR.DocFetcher hat sich über viele Jahre hinweg einen sehr guten Ruf erarbeitet und galt im Bereich der Freeware lange Zeit als nahezu konkurrenzlos. Die kostenfreie Version ist weiterhin verfügbar, die aktive Weiterentwicklung erfolgt inzwischen jedoch in der kostenpflichtigen DocFetcher Pro-Version (ab ca. 40 US-Dollar).
In einem ersten Test der Freeware-Version zeigte sich ein ähnliches Bild wie bei unseren vorherigen Vergleichen: DocFetcher fand deutlich weniger passende Dateien als Findit 6. Da der Autor jedoch ausdrücklich damit wirbt, dass die Pro-Version hier deutlich leistungsfähiger sei, haben wir diese erworben, um Findit 6 mit der bestmöglichen Version von DocFetcher zu vergleichen.
Testaufbau
Wie bei allen bisherigen Tests nutzen wir das über mehr als 30 Jahre gewachsene Archiv eines Journalistenbüros mit rund 50.000 Dateien und einer Gesamtgröße von etwa 50 GB. Enthalten sind Dokumente aus vielen Jahrzehnten, unterschiedliche Office-Formate, PDFs, gespeicherte E-Mails mit Anhängen verschiedenster Art sowie einige ZIP-Archive – kurz: ein reales, heterogenes Archiv aus dem Arbeitsalltag.
Datenbestand:
D:\Archiv (heterogen, historisch gewachsen, ca. 50.000 Dateien)Suchanfrage: Dateien UND finden
DocFetcher-Version: DocFetcher Pro (kostenpflichtig, ca. 40 USD)
DocFetcher – erster Indexlauf
Nach der Installation präsentiert sich DocFetcher mit einer sehr stark reduzierten Benutzeroberfläche, die weitgehend ohne klassische Menüs auskommt. Zentrale Funktionen erschließen sich erst nach genauerem Hinsehen; erst über einen Klick auf „Suchbereich" lässt sich ein neuer Index anlegen.
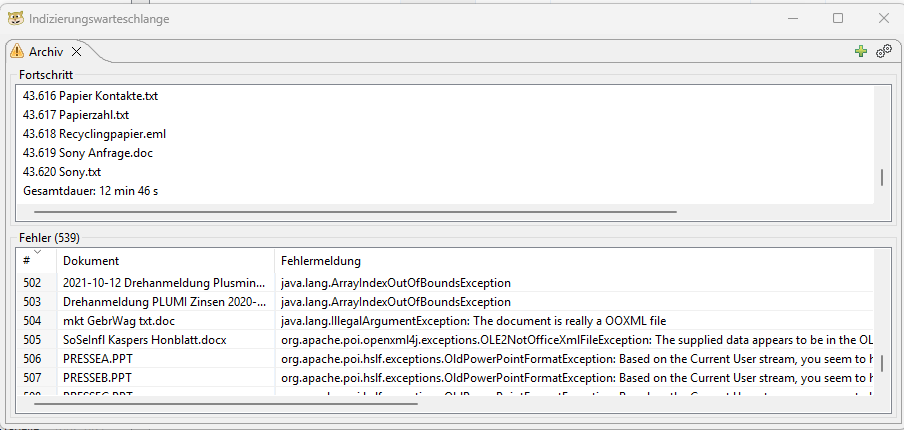
Wir haben zunächst einen Index mit den nach der Installation vorhandenen Standardeinstellungen erstellt. Nach gut 8 Minuten war der Indexlauf abgeschlossen. DocFetcher meldete dabei allerdings nur rund 43.000 indizierte Dateien, obwohl sich im Archiv eindeutig mehr als 50.000 Dateien befinden – bei Einbeziehung von Maildateien und Inhalten aus ZIP-Archiven sogar noch deutlich mehr.
Zusätzlich wies DocFetcher auf 539 Dateien hin, deren Inhalt nicht gelesen werden konnte. Als Ursache wurden überwiegend sehr alte Word-Formate sowie vermeintlich beschädigte HTML-, PDF- oder XLS-Dateien genannt. Das entspricht etwa rund einem Prozent des gesamten Datenbestands und erschien uns zunächst plausibel.
Bei ersten Suchtests zeigte sich jedoch, dass DocFetcher trotz abgeschlossenem Indexlauf durchgängig weniger Treffer lieferte als Findit. Auffällig war zudem, dass keinerlei .eml-Dateien (gespeicherte E-Mails) gefunden wurden.
Es ist bekannt, dass DocFetcher – anders als Findit – Mailanhänge nicht separat auswerten kann. Dass jedoch auch die eigentlichen Maildateien selbst nicht berücksichtigt wurden, war zunächst überraschend.
Erweiterte Indexkonfiguration als Workaround
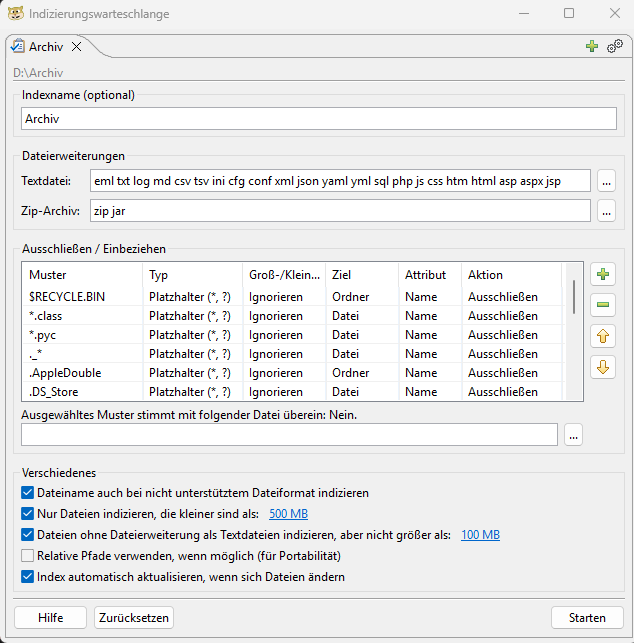
Bei weiterer Analyse wurde deutlich, dass DocFetcher Inhalte nur dann zuverlässig auswertet, wenn das jeweilige Dateiformat vollständig unterstützt wird. Für viele gängige Dokumenttypen ist dies der Fall, für einige in unserem Archiv vorhandene Formate – darunter auch .eml – jedoch nicht.
Bei der Erstanlage eines Indexes (und nur in diesem Moment) bietet DocFetcher allerdings die Möglichkeit, beliebige Dateiendungen als Textdateien zu definieren. Dateien mit diesen Endungen werden dann ohne besondere Formatinterpretation als reiner Text eingelesen und indiziert.
Da .eml-Dateien technisch tatsächlich textbasiert gespeichert sind, bedeutet dies: Neben technischen Kopfzeilen werden auch Absender, Empfänger, Betreffzeilen und der eigentliche Mailinhalt wortweise erfasst. Zwar werden dabei auch strukturierte Zusatzinformationen mitindiziert, für die reine Auffindbarkeit von Inhalten stellt dies jedoch keinen Nachteil dar.
Um für unseren Vergleich möglichst faire und vergleichbare Bedingungen herzustellen, haben wir diese Möglichkeit genutzt und alle in unserem Archiv vorkommenden, sinnvoll als Text interpretierbaren Dateiendungen – einschließlich .eml – explizit als Textdateien konfiguriert. Anschließend wurde der Index vollständig neu erstellt.
Uns war wichtig, DocFetcher nicht mit seinen Standardeinstellungen zu bewerten, sondern zu zeigen, welche Ergebnisse unter optimalen, aber realistisch erreichbaren Bedingungen möglich sind. Gleichzeitig wird damit deutlich, welcher Aufwand notwendig ist, um bei sehr heterogenen Archiven eine möglichst vollständige Inhaltsdurchsuchung zu erreichen.
Der erneute Indexlauf dauerte 12 Minuten und 46 Sekunden und war damit weiterhin recht schnell. Allerdings änderte sich weder die Zahl der als indiziert gemeldeten Dateien (43.620) noch die Zahl der gemeldeten Fehler (539). Nun denn, mehr konnten wir hier nicht tun.
Suche mit enttäuschendem Ergebnis
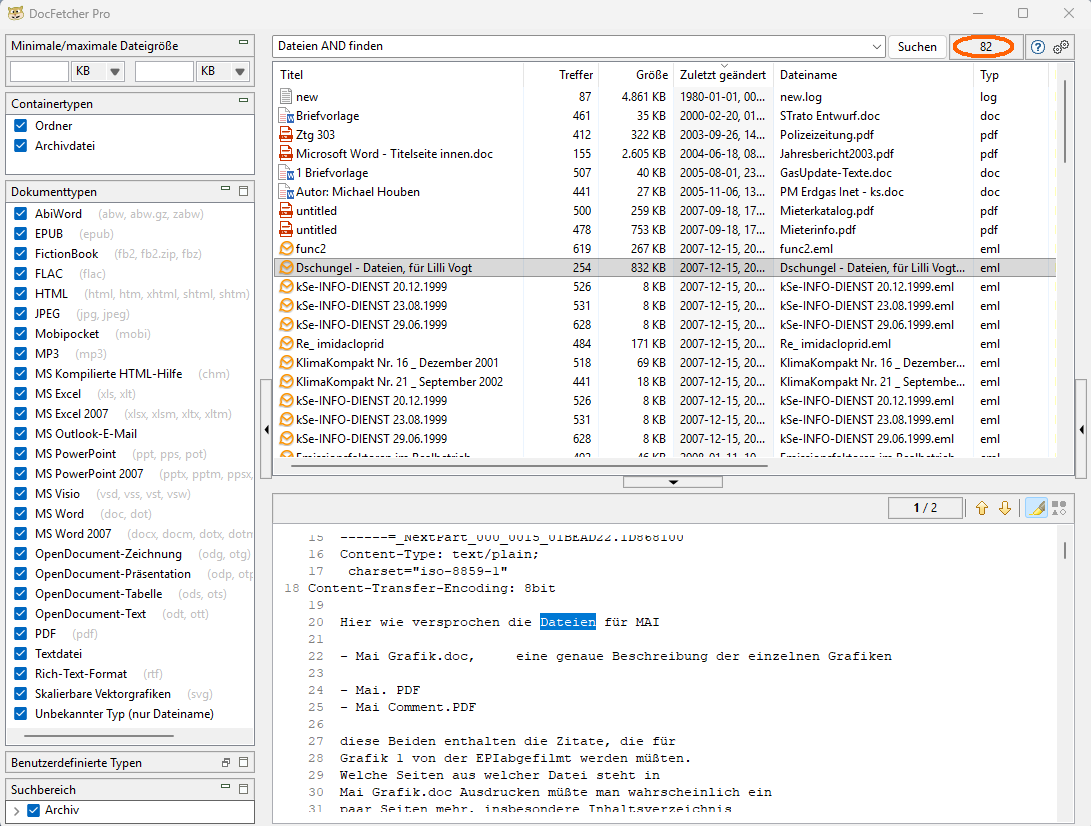
Angesichts des betriebenen Aufwands waren wir vom Ergebnis dann doch enttäuscht: Mit unserer Standardsuche nach Dateien, die sowohl „Dateien" als auch „finden" enthalten, fand DocFetcher lediglich 82 Dateien. Positiv ist, dass nun auch entsprechende gespeicherte E-Mails enthalten waren. Dennoch fehlten zahlreiche andere Dateiformate.
DocFetcher Pro – Nach optimierter Indexierung
So wurde beispielsweise nur eine einzige Datei gefunden, die vor dem Jahr 2000 entstanden ist, wobei auch unterschiedlichste deutlich neuere Dokumente – darunter auch einzelne moderne Office-Dateien – nicht auftauchten.
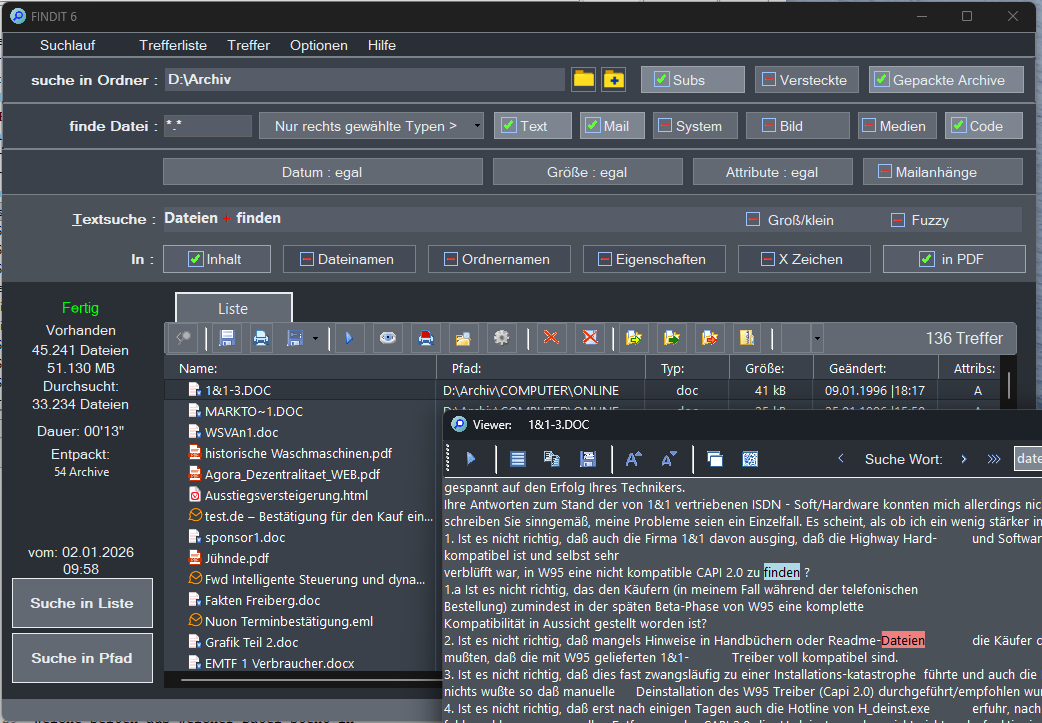
Zum Vergleich: Wir wissen, dass DocFetcher – anders als Findit – weder Mailanhänge durchsuchen noch OCR einsetzen kann. Doch selbst wenn man diese Optionen in Findit deaktiviert, findet Findit in unserem Datenbestand 136 passende Dateien (Suchdauer: ca. 13 Sekunden). Mit allen aktivierten Optionen sind es sogar 172 Treffer (in rund 26 Sekunden). Damit konnte DocFetcher nicht einmal die Hälfte der tatsächlich auffindbaren Dateien anzeigen.
Auch bei einer Suche nach nur einem einzelnen Wort, hier erneut „Dateien", zeigte sich ein ähnliches Bild. Während Findit (ohne Mailanhänge und OCR) 643 passende Dateien fand und SeekFast am Vortag immerhin 499 Treffer lieferte, listete DocFetcher lediglich 274 Dateien auf.
Offensichtlich hat DocFetcher – anders als SeekFast – kein grundsätzliches Problem mit der Verknüpfung mehrerer Suchbegriffe. Sein Index ist jedoch so aufgebaut, dass viele Dateien aus ganz unterschiedlichen Gründen gar nicht oder nur unvollständig erfasst werden und damit auch nicht gefunden werden können.
Wenn man bei einer Suche noch einige hundert Treffer erhält, wirkt das zunächst durchaus „ausreichend". Sobald man jedoch nach Begriffen sucht, die nur in wenigen, speziellen – und dann meist auch besonders wichtigen – Dokumenten vorkommen, steigt auch bei DocFetcher das Risiko deutlich, dass genau diese Dateien vollständig verborgen bleiben.
Kurzfazit
Stärken & Schwächen
Stärke: Open Source, etabliert, Pro-Version mit erweiterten Funktionen
Schwäche: Trotz manueller Optimierung nur 48% der tatsächlich vorhandenen Treffer gefunden
Im Test kritisch: Index-basierter Ansatz führt zu massivem Datenverlust durch unzureichende Parser
Direkter Vergleich
| Programm | Treffer (2 Wörter) | Treffer (1 Wort) | Vorbereitung |
|---|---|---|---|
| Findit 6 (alle Optionen) | 172 | 855 | Keine (26 Sek.) |
| Findit 6 (ohne Mail/OCR) | 136 | 643 | Keine (13 Sek.) |
| DocFetcher Pro | 82 | 274 | 12:46 Min. Index |